JavaScript SEO
customers every day for businesses just like yours.


JavaScript can be used to create dynamic web pages that improve your site’s UX, but it can also create complications when it comes to crawlability and indexability. Our team has a deep understanding of how search engines work and how to optimise JavaScript to ensure it is properly indexed. We will ensure your Javascript does not impact your SEO performance, and we will avoid common issues such as slow rendering speed, blocked scripts, and content duplication.
Get the Data-Driven Insights Your Website Needs – Try Our Free SEO Audit Tool
The Complete Guide to JavaScript SEO (We mean It!)
When looking for information related to JavaScript SEO, you may come across hundreds of posts. Yet, there’s an air of uncertainty on whether search engines can render and index JS pages. If you feel so, trust me it’s a normal feeling!
With the rise of Javascript frameworks , SEOs have struggled to minimize its not-so-desirable impact on their search performance. Plus, whether or not Google can process JS content is still a shaky subject in the search world.
Search engines claim to have made considerable progress in processing JavaScript content; yet, several issues, uncertainties, and misunderstandings cause many SEOs to have doubts about JS, making them wonder whether their JavaScript SEO strategies will work.
This post is an answer to all your concerns regarding JavaScript SEO. I assure you, by the end of this detailed guide you will have no qualms about optimizing your JS content.
So, let’s get started!
JavaScript: The Dominant Language That Powers the Web Today!
We live in an era where users expect dynamic content. So, if your website holds text-heavy static content, you’ll find it tough to gain an edge over your competitors. This is precisely what made JavaScript popular!
JS is a powerful, dynamic, and flexible programming language that can be implemented on a variety of web browsers. It’s the cornerstone of modern web development that offers interactivity to web pages in the browser.
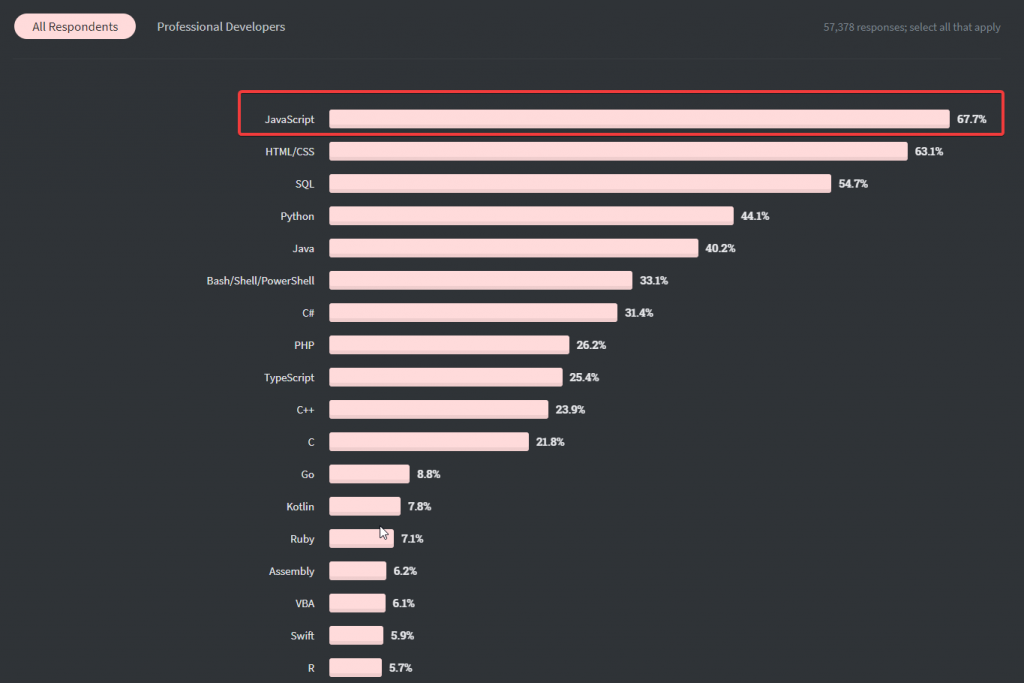
This influential programming language can be used to build a wide range of applications. Though developers prefer this language for several reasons, we have three primary reasons for JavaScript’s domineering popularity.
- It can be used both on the client and server-side. As a result, developers find it easy to use the programming language along with other server-side languages like PHP.
- It is a cross-platform programming language. For instance, you can build applications for desktop and mobile platforms using various frameworks and libraries.
- It enjoys large community support of JavaScript enthusiasts.
Why Should JavaScript Content Matter to SEOs?
Most brands have adopted JS for creating complex dynamic pages in place of static content. This greatly improves the site’s UX.
However, SEOs should know that, if they do not take the necessary measures, JS can affect their site’s performance in terms of its –
- Crawlability – A search engine crawler’s ability to navigate a website, page by page. JavaScript can limit the extent to which a crawler can find and index JS content.
- Indexability- If a crawler reads your page but is unable to process the content it will prevent your content from ranking for the relevant keywords.
JavaScript rendering is a complicated and resource-intensive task that directly impacts UX factors and finally the SEO of a website. It can affect a site’s SEO performance through the rendering speed, the main thread activity, blocked scripts, content duplication, user events, and service workers among others.

OUR SEO PROCESS
The First Page of Google!
Research
In this phase, our SEO consultants will work with you to understand your business and define the goals of our SEO campaign. We will perform competitor research and search intent analysis before identifying the keywords that we think you should target.

Audit
Our comprehensive SEO audit looks at everything from content gap analysis and internal links to site architecture, backlink profiles, technical SEO, and crawl optimisation. Our team will identify all the growth opportunities based on your current website and SEO performance.

Strategy
In the strategy phase, we evaluate the findings from our audit and prioritise SEO tasks. We have an Impact / Effort / Action Priority Matrix that we follow to prioritise tasks. Our SEO specialists create an action plan for your SEO campaign, which includes a timeline with key milestones we have to achieve.

Implementation
Our SEO team, designers and developers work with you to start actioning the high priority tasks from the previous phase. Following this, we get onto the low priority tasks. This process allows us to knock out some early quick wins, then have a strategy in place to tackle the high effort tasks. We keep the low rewards tasks on the back burner and tackle them when we get time as the campaign progresses.

Reporting
We have systems and processes in place to make sure that we track and report on your SEO campaign.
As you can imagine, this is not the end. Our SEO consultants are constantly analysing and tweaking your campaign to achieve the best possible results on the 1st page of Google. It is an ongoing process, and we are with you for the long term!

Research
In this phase, our SEO consultants will work with you to understand your business and define the goals of our SEO campaign. We will perform competitor research and search intent analysis before identifying the keywords that we think you should target.
Audit
Our comprehensive SEO audit looks at everything from content gap analysis and internal links to site architecture, backlink profiles, technical SEO, and crawl optimisation. Our team will identify all the growth opportunities based on your current website and SEO performance.
Strategy
In the strategy phase, we evaluate the findings from our audit and prioritise SEO tasks. We have an Impact / Effort / Action Priority Matrix that we follow to prioritise tasks. Our SEO specialists create an action plan for your SEO campaign, which includes a timeline with key milestones we have to achieve.
Implementation
Our SEO team, designers and developers work with you to start actioning the high priority tasks from the previous phase. Following this, we get onto the low priority tasks. This process allows us to knock out some early quick wins, then have a strategy in place to tackle the high effort tasks. We keep the low rewards tasks on the back burner and tackle them when we get time as the campaign progresses.
Reporting
We have systems and processes in place to make sure that we track and report on your SEO campaign.
As you can imagine, this is not the end. Our SEO consultants are constantly analysing and tweaking your campaign to achieve the best possible results on the 1st page of Google. It is an ongoing process, and we are with you for the long term!

How Google Processes JavaScript Content
Is Javascript bad for SEO? Honestly, it depends on several factors. But when JS is primarily being used to render important pages, the answer’s yes! Let’s dig deeper into how Google processes JavaScript and its impact on your site’s SEO.
Google bots do not crawl JavaScript pages in the traditional sense. They can only crawl the static HTML source code. So, when a bot comes across content rendered with JS, it has to follow a few steps to render the content – crawling, rendering, and indexing.
Here’s what happens when bots reach a regular HTML/ non-JS page.
- The bot downloads the raw HTML file for your page.
- It passes the HTML to Caffeine (the indexer) to extract all the links and metadata.
- The bot continues to crawl all the discovered links.
- Caffeine indexes the extracted content that is further used for ranking.
Fortunately, Caffeine can now render JS files like a browser would (through Google’s Web Rendering Service). So, here’s how Google with its WRS reaches your JS-powered pages.
- The bot downloads the raw HTML file for your page.
- The first indexing occurs instantly without the rendered content. Simultaneously, Caffeine works on rendering the JavaScript page.
- The extracted links, metadata, and content are passed back to the bots for further crawling.
- The extracted content is indexed during the second indexation process and used for ranking.
The following image shared by Google in its brief guide on JavaScript SEO summarizes the process. However, it’s important to note that the bots will crawl and index any HTML page it finds along the way.
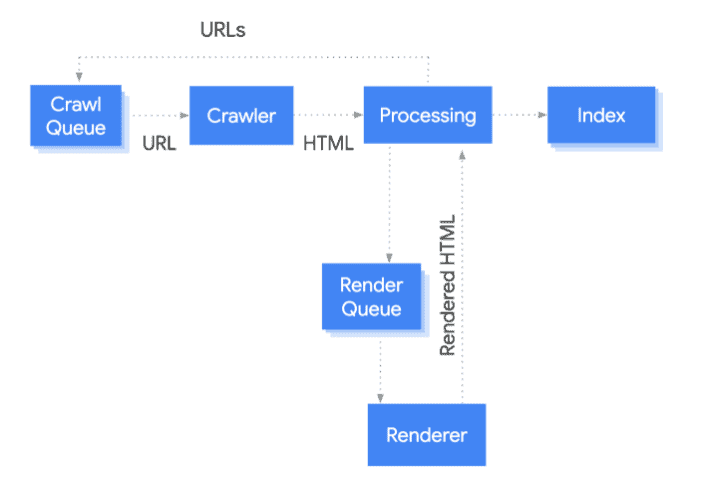
Let’s look at each of these in detail.
Crawling
To begin with, the Google bot fetches a URL for a page from the crawling queue and checks if it allows crawling. Assuming that the page isn’t blocked in the robots.txt file, the bot will follow the URL and parse a response for other URLs in the href attribute of HTML links.
If the URL is marked disallowed, then the bot skips making an HTTP request to this URL and ignores it altogether.
Rendering or Processing
At this stage, the URL is processed for JavaScript. The page is placed in the render queue.
Once it’s rendered, the bots will add the new URLs it discovers to the crawl queue and move the new content (added through JS) for indexing.
There are two types of rendering – server-side and client-side rendering.
- Server-Side Rendering (SSR)
In this type of rendering, the pages are populated on the server. So, every time the site is accessed, the page is rendered on the server and sent to the browser.
Simply put, when a visitor or a bot accesses the site, they receive the content as HTML markup. So, Google doesn’t have to render the JS separately to access the content, thus improving the SEO.
- Client-Side Rendering (CSR)
Client-side rendering is a fairly recent type of rendering that allows SEOs and developers to build sites entirely rendered in the browser with JS. So, CSR allows each route to be created dynamically in the browser.
CSR is initially slow as it makes multiple rounds to the server but once the requests are complete the process through the JS framework is quick.
Indexing
At this stage, the content (from HTML or new content from JS) is added to Google’s index. So, when a user keys in a relevant query on the search engine, the page will appear.
Case Studies
Return on Investment for business owners.






JS Errors That Impede SEO
JavaScript is extremely popular as it allows developers to build websites using exciting features. Yet, a few errors can harm your site’s SEO and negatively impact your ranking. Upon carefully studying the list, we recommend that you regularly conduct a JS website audit. It will allow you to timely detect the errors that could impede your website’s growth. When ignored, such errors can prevent you from getting a decent Core Web Vitals score, lead to Google not indexing big portions of your content or even not crawling parts of your sites at all. Here are a few JS errors you should pay attention to and avoid at all costs.
- Abandoning HTML CompletelyIf your most important information is within JavaScript, the crawlers will have little information to work with when they first index your site. Hence, the critical information you want to be indexed should be created using HTML.If you aren’t sure where your critical content lives, inspect your page source by right-clicking anywhere on the page. Next, select ‘Inspect’ from the menu. The content you see on the inspect page is the one that the bots can see. Alternatively, turn JavaScript off in your browser to see what content remains.
- Blocking JavaScript from robots.txt In the past, search engine bots couldn’t crawl JS files. Hence, webmasters often stored them in directories and blocked robots.txt. However, this isn’t needed now as Google bots can crawl JS and CSS pages.To check if your JS files are accessible to the bots, log in to Google Search Console and inspect the URL. Unblock the robots.txt access to fix this issue.
- Not Using Links ProperlyLinks help Google’s spiders understand your content better. They also get to know how the various pages on the site connect. In JS SEO, links also play a critical role in engaging users. So, not placing the links properly can negatively impact your site’s UX. Therefore, it’s advisable to set up your links properly.Use relevant link anchor text and HTML anchor tags, including the URL for the destination page in the href attribute. Also, steer clear of non standard HTML elements and JS event handlers to linkout as they can make it tough for users to follow the links and impact the UX, especially for those using assistive technologies. Also Google bot will not follow those links.
- Placing JS Files above the Fold JavaScript file load in the order of appearance. Rendering JS files takes time as the browser needs to request the script file and wait till it’s downloaded from the server. So, placing JS above the fold will cause it to interfere with the site load speed, thus leading to poor UX and slow page crawling.Gauge the importance of JS content. If it’s worth making the users wait for it, place it above. Else, it’s wise to place them lower on the page and above the fold space.
- Improper Implementation of Lazy Loading/ Infinite ScrollingNot implementing lazy loading and infinite scrolling properly can come in the way of bots when they crawl content on a page. These two techniques are great for displaying listings on a page but only when done correctly.
- Using JS Redirects Using JS redirects is a common practice among SEOs and developers as the bots treat them as standard redirects and can process them. However, these redirects significantly reduce site speed and UX. JS is crawled in the second phase; so, JS redirects may take longer (days or maybe weeks) to get crawled or indexed.Hence, it’s best to avoid JS redirects.Finally, stop blaming JavaScript for anything that goes wrong with your SEO. Google’s Martin Splitt points out in a live session with Search Engine Land that most SEOs blame JS even when the issue lies elsewhere.


JavaScript is search engine friendly, provided you take care not to commit the above-mentioned errors.

Client Testimonials
about Our Digital Marketing Services.
- 428 Google Reviews
- 4.9


Extremely reliable and super friendly staff. Jani and Sam helped us with our digital strategy. Would recommend to everyone who wants to get their SEO done.

Mark, Ron and Param from have been incredible to work with. From the very beginning, they took the time to understand our business goals and crafted a clear SEO strategy that is working really well.

Mark and Jani are fantastic to deal with and business has never been better

We are super impressed with this SEO team. They’re honest, transparent, and really know their stuff. They made everything easy to understand and were great to work with from the start. We saw our targeted keywords hit page one with half of them in the #1 spot, and organic traffic is up by nearly 20%. We recommend Supple for fast and high quality results.

I have to speak very highly of the crew of Supple Digital, Mark, Jani and Abbas do an amazing job of my website. Very highly professional and knowledgeable of their products and services. If you are in need of a good website go to these guys
View More Reviews
-
Nazir Mohammadi9 months ago
Extremely reliable and super friendly staff. Jani and Sam helped us with our digital strategy. Would recommend to everyone who wants to get their SEO done.
-
Hunter D'Angelis1 year ago
Mark, Ron and Param from have been incredible to work with. From the very beginning, they took the time to understand our business goals and crafted a clear SEO strategy that is working really well.
-
David Whitewayy1 year ago
Mark and Jani are fantastic to deal with and business has never been better
-
P Pond1 year ago
We are super impressed with this SEO team. They’re honest, transparent, and really know their stuff. They made everything easy to understand and were great to work with from the start. We saw our targeted keywords hit page one with half of them in the #1 spot, and organic traffic is up by nearly 20%. We recommend Supple for fast and high quality results.
-
Carlo Marek1 year ago
I have to speak very highly of the crew of Supple Digital, Mark, Jani and Abbas do an amazing job of my website. Very highly professional and knowledgeable of their products and services. If you are in need of a good website go to these guys
View More Reviews

Chris Nasr
MCN Plumbing
Stuart Lancaster
Maroondah Air
Darran Yeow
Insightful Eye Care
Adam Wilson
Stride Group
Mark Ottobre
Enterprise Fitness
Clayton Blackman
KRGS Doors
Top JavaScript SEO Strategies
Knowing how to tackle the challenges and get the most of JavaScript is vital for modern SEOs. Here are a few strategies that can help you navigate the world of JavaScript SEO.
- Continue Your On-Page SEO EffortsAll the on-page SEO guidelines related to the content, title tags, meta descriptions, alt attributes, and meta robot tags among others still apply.For instance, unique and descriptive titles and meta descriptions help users and crawlers process the content with ease.Similarly, using short descriptive URLs is one of the best on-page SEO tactics that get the most clicks as they match the search query.
- Fix Duplicate Content Multiple URLs with the same content is a common occurrence with JavaScript heavy sites. Such duplicate content issues are caused by capitalization, IDs, and parameters with IDs among other factors.Duplicate content doesn’t add any value to a site’s SEO; in fact, it confuses the crawlers and increases the risk of important pages being ignored by Google. Make sure you choose a version you want the crawlers to index and set canonical tags to fix duplicate content.
- Use Meaningful HTTP Status CodesHTTPS status codes like a 404 or 401 are used by the bots to determine if something went wrong during the crawling process. Use meaningful status codes like the ones shared below to inform the bots whether a page needs to be crawled or indexed.
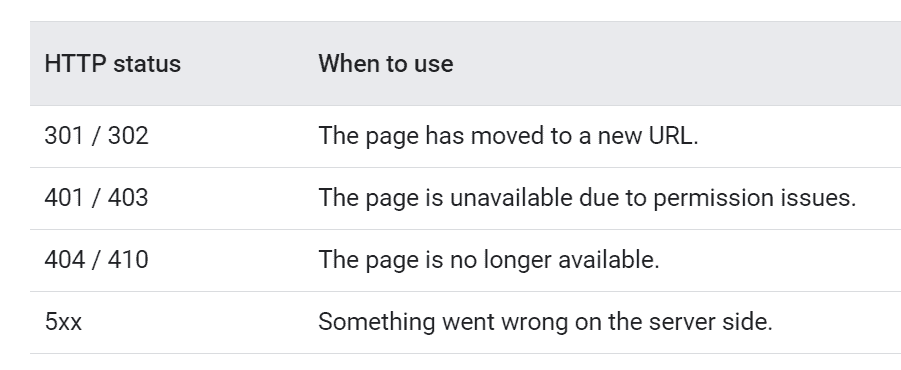
For instance, you can use a 301 or 301 status code to tell Google bots that the page has moved to a new URL. This will help the bots update the index accordingly.
- Employ Clean URLs and MarkupJavaScript can dynamically alter or update content or links on a webpage, causing confusion for the search engine bots. Therefore, it’s important to use clean URLs and links with the <a href> attribute. This will ensure that your pages are easily discoverable.The same applies to markup. So, make sure that the key markup is structured clearly and is included in the HTML for page titles, meta descriptions, canonical tags, alt attributes, and image source attributes among others.
- Improve the Page Loading Speed Page speed is one of the critical ranking signals used by Google to rank pages. A website that loads quickly helps bots with the overall indexation process and improves UX. However, this can be an issue with JavaScript. Mitigate this issue by using lazy loading for certain components.Images often eat up the bandwidth and negatively impact the site performance. Use lazy loading to load images, iframes, and non-critical content only when the user is about to see them.However, if not implemented correctly, lazy loading can hide critical content from the bots. Use this lazy-loading guide by Google to ensure that the bots crawl all your content whenever it’s visible in the viewport.
- Conduct a JS Website AuditThis means conducting a routine manual inspection of the individual elements using the Google Developer Tools from Google Chrome and the Web Developer Extension for Chrome. Here’s what you can include as a part of this audit.
- Visual Inspection: This will help you get an idea of how a user views your site. Check elements like the visible content on the site, hidden content, content from third parties, and product recommendations. The goal is to make these elements crawlable.
- Check HTML Code: Turn off the CSS, JavaScript, and cookies to check the balance code that’s controlled by JS.
- Check the Rendered HTML: Load the site with deactivated JavaScript and CSS. Next, right-click and choose ‘Examine element’ in the Chrome menu. Click on the HTML tag on the right-side for the ‘Options’ menu.
Choose ‘Copy External HTML.’ Finally, insert the code into the editor to allow the code to be indexed by the search bots. You can also test JavaScript with the Google Search Console using the URL inspection tool.
Finally, make sure you avoid the common errors in JavaScript SEO we discussed earlier in this post.
SEO Team Lead
company's online marketing goals.
- Bishal Shrestha
- Head of SEO (9+ Years Experience)
Bishal Shrestha is an innovative SEO leader and digital strategist with over 9 years of expertise in driving organic growth for businesses across diverse industries. Bishal combines technical proficiency with strategic vision, excelling in data-driven decision making and delivering measurable results. He specialises in technical SEO optimisation, advanced analytics, and scalable growth strategies.
Bishal brings a unique blend of software engineering background and marketing acumen to his role at Supple Digital. With certifications in Google AdWords and Google Analytics, he leads comprehensive SEO campaigns that consistently elevate brands in competitive digital landscapes. His holistic approach focuses on sustainable, long-term growth through innovative solutions.

Common JS and SEO Myths You Should Ignore
JavaScript SEO has changed and advanced over years. So, the only misconceptions surrounding it are the outdated practices used by developers and SEOs who have failed to change their strategies despite the algorithm updates. We are busting four such myths for you so that you can plan and execute a perfect JavaScript SEO plan for your website.
Myth 1: Google Cannot Crawl JavaScript
While it’s true that Google bots found it challenging to crawl JS pages in the past, improvements in its algorithm have made its crawlability quite effective.
Today, Google is the best search engine for reading JS content. Other search engines like Bing, Baidu, and Yandex still have a long way to go in terms of crawling JS pages. So, if your site has more Bing traffic, it’s wise to focus on a non-JS-based web development plan for now.
Myth 2: Mobile Sites Should Consider Cutting Off JS
Web developers trying to boost mobile speed and create a mobile-friendly site may consider banishing bulky JS code. However, it’s possible to include this code without hurting your mobile SEO.
For instance, Google offers three types of configurations that can be used to serve JS code to mobile users.
- JavaScript-Adaptive: This configuration is recommended by Google. The same HTML, CSS, and JavaScript content is served but the rendering is altered based on the device.
- Combined detection: This configuration uses JS but also has server-side detection of devices. So, it can serve content differently on each option.
- Dynamically-Served JavaScript: This configuration serves the same HTML but the JS is altered based on a URL that identifies the device.
Using such tools to add JS to mobile devices can make your site mobile-friendly.
Myth 3: You Should Block Crawlers From Reading JS
Most SEOs are found guilty of blocking bots from crawling Javascript code accidentally. Others do this deliberately to improve their site’s readability.
If the bots focus primarily on HTML, they should have an idea of the content and the site layout. But that’s not the case. The bots need to access JS files to –
- Render the page completely and make sure it’s mobile-friendly
- Ensure that the content isn’t buried under disruptive ads
- Keep an eye on black-hat practices like keyword and link stuffing
So, you may be under the impression that blocking Javascript improves the site’s experience but in reality, you are frustrating the crawlers (and even violating Google’s search terms!) by doing so.
Myth 4: JavaScript SEO Demands Advanced Development Skills
Adding readable JS is easier than you think. You don’t have to be an expert in JS and SEO to build a site that can attract traffic and engage an audience. If you are struggling with platform limitations that impact your SEO, get in touch with a professional SEO consulting firm that can review your JS delivery opportunities and improve your SEO performance.

Popular Articles
Our Blog Is A One-Stop-Shop for Free Advice and
Comprehensive Guides
The Supple team publishes new articles, case studies, and guides all the time. Learn more about digital marketing with our experts.



JavaScript SEO – Frequently Asked Questions
Here are a few questions we commonly come across on JavaScript SEO. We have attempted to share satisfying answers to each. But in case you have any queries on JS SEO, feel free to get in touch with our team!
- What Happens If I Don’t Do JS SEO?
Though Google is improving its ability to index JS content, there’s still no surety that the content will be indexed. There are several caveats in Google’s ability (not even talking about other search engines and social channels here!) to process JavaScript content.
This makes it imperative for webmasters depending on JavaScript to make sure that search engines can access, render, and index their content with ease.
- Can I Do Something to Reduce JavaScript’s Impact on Web Performance?
Yes! Techniques like code minifying and compressing, caching, and tree shaking can be used to reduce the necessary bandwidth usage and boost web performance. For instance, tree shaking is a form of dead code elimination that can significantly reduce JS payloads and improve the site’s performance.
- In Light of JS SEO, Is PWA SEO Required?
Using JS as a PWA or Progressive Web Application framework ensures the best possible UX. However, there have been concerns about creating a crawler-friendly JS application.
PWA is a form of application software that is delivered through the web and built on web technologies like HTML and JS. Hence, ideally, all the recommendations applied to JS sites should work with PWAs too. However, the Google Web Rendering service has Service Workers (one of the pillars of the PWA architecture) disabled.
Like JS SEO, PWAs also need to be optimized as they need to be SEO compatible and indexed properly. PWA SEO is possible; however, Google should be able to render JS pages for it to be able to view the content present in the PWA.
Talk to an expert SEO agency that can help get your PWA indexed and make them discoverable.
- How Mobile-First Indexing Affects JS Pages?
Mobile-first indexing is Google’s indexing system that first considers the mobile version of a website. So, if the desktop version of your website is fully optimized but your mobile version uses poor JavaScript SEO practices, your website ranking will suffer.
So, it’s critical to audit your site’s desktop and mobile versions, allowing Google bots to easily index your pages.
- If Google Cannot Deal with the Client-Side Rendered Website, Can I Serve It a Pre-Rendered Version of My Website?
Yes! Serving Google bots a pre-rendered version is a workaround solution to allow the crawlers to successfully and immediately process JavaScript content. The process is referred to as dynamic rendering and it’s officially accepted and supported by search engines like Google and Bing.
Check out this video for more information on dynamic rendering.

- Google Constantly Claims to Fix the Issue Related to the Crawlers Processing JS Content. So, Will JS SEO Not Be Relevant in the Future?
JavaScript SEO is here to stay! Here’s what Google’s John Mueller had to say about it in one of his tweets.
As new technologies and frameworks are introduced, JS SEO will only get more technical, increasing the demand for SEO experts who can optimize JS content. Already,97 percent of all websites use JavaScript. Mastering JS SEO will only help you supersede competition and improve your site’s ranking.
Google’s URL Inspection Tool helps SEOs determine whether or not Google is rendering its web pages. You can run live tests to see real-time JS warnings and errors that were coming in the way of your pages being indexed or discovered.
Mobile-Friendly Test
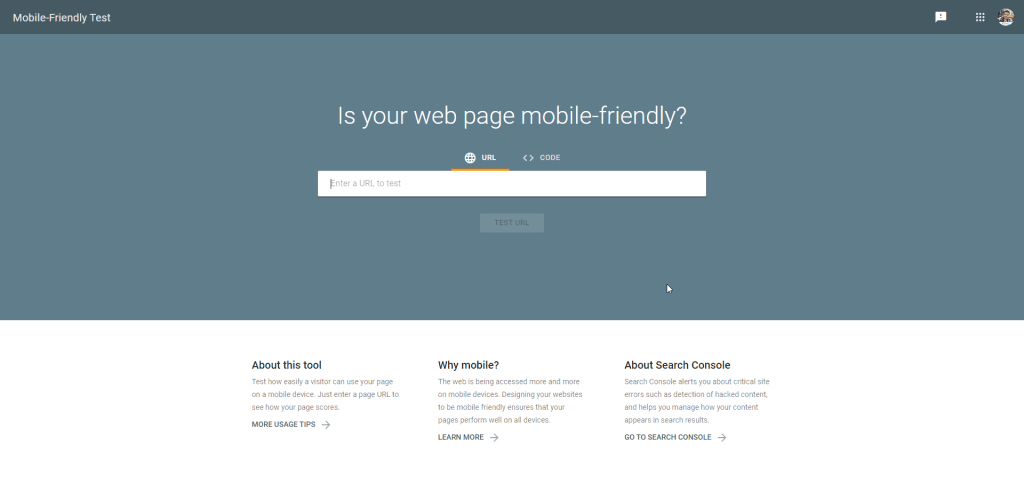
You can use this test to determine whether your pages render on smartphones. For this, you do not need a Google Search Console account. The test also points out the errors or blocked resources stopping crawlers from accessing your content.
- Data Comparison Tools
Tools like Diffchecker, Guesty, and Microsoft Flow can perform a quick analysis of a web page’s source code vis-a-vis its rendered code. This comparison offers insights into how the content changes once it’s rendered.
Further, Chrome Extensions like View Rendered Source helps webmasters compare the raw HTML source of a page to the browser rendered DOM. It also shows the difference between the two.
- SEO Crawlers and Log Analyzers
SEO spider tools like DeepCrawl, Screaming Frog, and JetOctopus can be used to get granular insights on each page and test/monitor rendering at scale.
- PageSpeed Insights
Google’s PageSpeed Insights tool uses a combination of data from Google Lighthouse and lab data to deliver insights related to speed and page performance. Besides, it offers JavaScript reports that show how a page could be optimized by reducing the JS execution time and minifying JS.
- Chrome DevTools
If you use Chrome as a primary browser, the debugging and JavaScript testing capabilities of Chrome DevTools can be used to generate a variety of reports. Performance monitoring and identifying JS errors can be easily achieved with this tool.
Awards and Recognition






Conclusion
JavaScript SEO continues to remain a sore spot for SEOs and webmasters worldwide. However, JS is the most popular programming language when it comes to executing a site with great UX and bringing interactivity and dynamism to the web. As a result, search experts and developers need to appreciate the complications and complexities encircling JavaScript and SEO and execute smart strategies that facilitate the indexing of JS pages in Google.
Use the information and strategies shared in this post to get the best of JavaScript and boost your online ranking.

Industries We Work With
Businesses Just Like Yours.

- Accountants SEO
-
- Asbestos Removal SEO
-
- Blinds & Shutters SEO
-
- Cosmetic Physician SEO
-
- Doctors SEO
-
- Financial Services SEO
-
- Flooring Companies SEO
-
- Healthcare SEO
-
- Heating & Cooling (HVAC) SEO
-
- Hotel & Accommodation SEO
-
- Laser Clinic SEO
-
- Locksmith SEO
-
- Office Fitout SEO
-
- Optometrists SEO
-
- Real Estate SEO
-
- Security Companies SEO
-
- Windows & Doors SEO
-
- Mechanic SEO
-
- Electrician SEO
-
- Lawyers SEO
-
- Fashion SEO
-
- SAAS SEO
-
- Dentist SEO
-
- Plumber SEO
-
- Florist SEO
-
- Nonprofit SEO
-
- Solar Installers SEO
-
- Kitchen Renovation SEO
-
- NDIS SEO
-
- Removalists SEO

- We Work With all business get in touch
Platform We Work With
Your SEO Campaign
DIGITAL MARKETING FOR ALL OF AUSTRALIA
- SEO AgencyMelbourne
- SEO AgencySydney
- SEO AgencyBrisbane
- SEO AgencyAdelaide
- SEO AgencyPerth
- SEO AgencyCanberra
- SEO AgencyHobart
- SEO AgencyDarwin
- SEO AgencyGold Coast
- We work with all businesses across Australia
Our Online Marketing Tools
and help you achieve online success.
