How to Get Rid of Duplicate Content? Tips to Aid Your SEO Strategy

Duplicate content is a common on-page SEO issue that sites face.
You may think that Google doesn’t penalise websites for duplicate content issues. So why fuss so much over it?
Sure, Google doesn’t levy penalties for duplicate content. But it can certainly weaken your SEO performance.
That’s why it makes perfect sense to control the content duplication on your site.
In this guide, we’ll learn:
- What exactly is duplicate content,
- Types and reasons of duplicate content,
- How duplicate content affects your SEO,
- How to find out duplicate content issues, and
- How to avoid duplicate content issues.
Let’s get started.
What is Duplicate Content?
Duplicate content is identical or word-for-word same content appearing on different pages within a website or across different sites.
Here’s how Google Webmaster Guidelines define duplicate content:
“Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content in the same language or are appreciably similar.”
Search engines aim to provide the best search experience to their users. So when search bots find multiple versions of the same content, they wouldn’t know which version to index and rank. So they may end up excluding all the versions while ranking.
While it may not cause a direct penalty from Google, a substantial amount of duplicate content can adversely affect your search engine rankings.
At the same time, it’s also worth noting that all duplicate content may not be deliberately copied to manipulate the search engines. With that in mind, let’s look at the reasons why content duplication happens on the same site and across different domains.
Duplicate Content Within a Site
This type of duplication can happen within your site and the same content may appear on multiple pages.
This could be due to the reasons like:
Variations in URL Structure
If you observe the below URLs, they all may look the same to you.
- https://www.domain.com
- https://domain.com
- http://www.domain.com
- http://domain.com
But Googlebot reads them as different URLs having the same content. So it may cause duplicate content issues.
Besides, some URL parameters like click tracking and analytics code can also cause duplicate content.
For example, you want to track the traffic source from social media campaigns for domain.com/page/ in Google Analytics. So you used the UTM parameters in the URL.
- domain.com/page?utm_source=facebook
This may also cause duplicate content.
Moreover, faceted navigation in eCommerce sites is yet another source of content duplication due to URL structure.
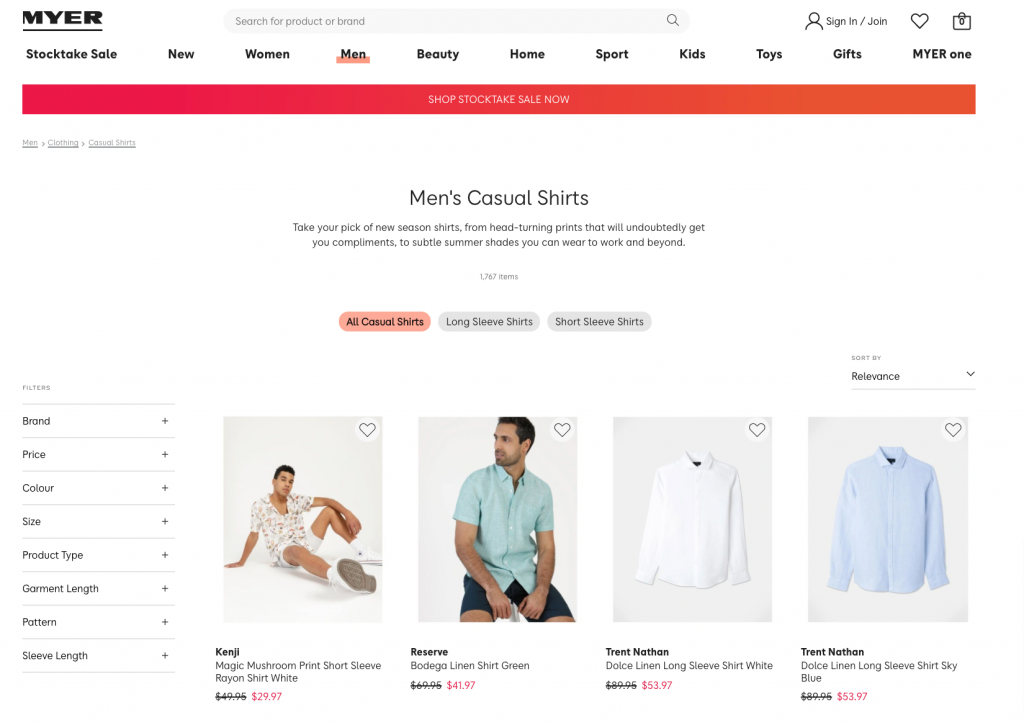
- myer.com.au/clothing/shirts.html?new_style=Checked&Size=S
- myer.com.au/clothing/shirts.html?Size=S&new_style=Checked
Here, the order of the parameters is different but the same page and content can be accessed with both URLs.
Domain Localization
Let’s say you’re running a business in multiple countries and have the local domain for each of the countries you operate in.
For instance, your site has a .com.au version for Australia and a .de version for Germany.
Apparently, the site content would overlap among these domains. And unless you translate the content in local languages, search engines may read them as duplicate content.
Duplicate Content Across Different Sites
Now let’s look at some of the factors that cause content duplication across multiple domains.
Boilerplate Content
Boilerplate is a non-malicious form of duplicate content. One example of such content is eCommerce product descriptions.
Sometimes the retailers simply copy-paste the product information provided by the suppliers. Now, these suppliers also sell goods to several other e-stores. Thus, many eCommerce sites end up having the same content in form of product descriptions.
This issue can be easily resolved if retailers rewrite the product specifications and benefits.
Copied or Scrapped Content
Some website owners deliberately copy the content from other sites to manipulate the search rankings and get traffic.
According to Google, it is a deceptive practice and it downgrades the user’s search experience when they see repetitive content on several sites.
Similarly, content scraping also involves stealing content from legitimate sites and publishing it on other websites. This is done by bots — also known as scrapers.
To protect your site from content scrapers, you can:
- Use CAPTCHA verification
- Install anti-bot applications
- Block the bots with JavaScript code, etc.
Content Syndication
Content syndication is republishing the same piece of content on other website/s that was originally published elsewhere. It has become a popular content distribution tactic and is done with the permission of the author. That’s why it’s called syndication.
For example, this article initially appeared on James Clear.

And then it was republished on another website.
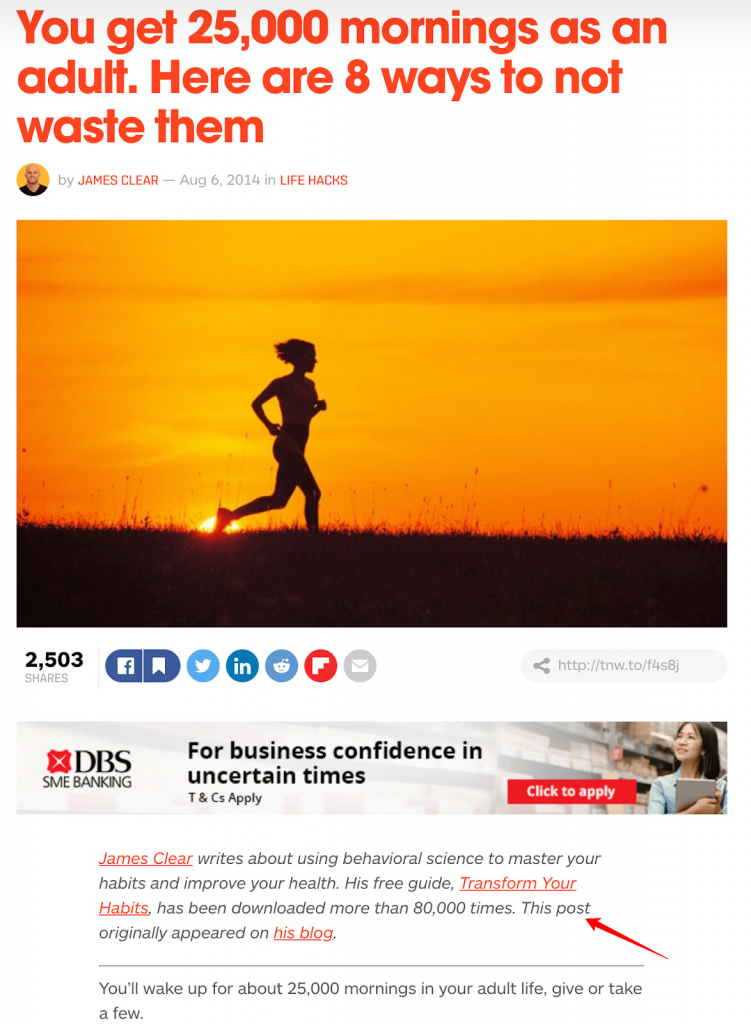
As you can see it also shows where it appeared first.
Although it creates multiple copies of the same content, Google doesn’t stop them from ranking as long as the republisher cites the original creator with appropriate anchor text.
How Does Duplicate Content Affect Your SEO?
Dilutes Link Equity
While you might be giving it all in building high-quality backlinks for your site, duplication can deprive the original content of the link juice benefits meant for it.
To simplify, let’s say when the same or similar content appears on multiple URLs, then all these URLs may get linked to.
Just imagine, an article within your site can be reached via multiple URLs. Something like this:
- https://domain.com/library/avoid-duplicate-content
- https://domain.com/resources/avoid-duplicate-content
Now some people may have accessed the article from the 1st URL while others may have reached there with the 2nd URL. This would divide the backlinks between these two URLs when they cite your article.
For instance, each of them earned 50 inbound links.
Had there been consistency in the URL structure, there would’ve been only one URL for this content and it would have earned 100 backlinks and thereby more page authority.
Wastes Your Crawl Budget
Search engines look for new and updated content through a process called crawling — scanning different pages on a site.
Based on the size and popularity, Google assigns a crawl budget for your site. It means that the Googlebot will crawl through only a limited number of pages on your site, not all of them.
So, if you have the same content on multiple pages of your site, bots may crawl the duplicate content URLs too. At the same time, the page with unique and important content may not get crawled at all.
Thus, duplicate content can burn your crawl budget on unnecessary pages.
Less Organic Traffic
Search engines don’t want to rank pages that copy content from other sources. However, as discussed earlier, sometimes search engines might not be able to differentiate between the original and duplicate content.
So when there are multiple pages with the same content, Google may not rank any of them in the search results.

As a result, the original page would get fewer organic visits.
Scrapped Content Outranking Original Content
Scrapers republish your content without taking your permission and giving the required attributes for the same. Again, this makes it difficult for the search engines to identify and rank the original content.
Hence, at times scrapped content can outrank your original piece and get all the benefits such as traffic, backlinks, etc. However, it’s a very rare occurrence.
Spammy Links
As a part of your SEO and content marketing strategy, you might be reaching out to various publishers for guest-posting — contributing content on other sites or blogs.
Some low-quality sites may paraphrase that content and use it on their website. This could lead to spammy links and websites pointing to your website.
This could result in a high spam score for your site’s backlink profile. So ensure you audit your backlinks at a regular interval and remove such toxic inbound links from your site.
Detecting Duplicate Content
Now let’s understand how you can detect duplicate content issues.
Search Blocks of Text
This is the most basic way to check if the content is copied from your site and being published elsewhere.
Just copy the random paragraph from your content and search for it in Google. It’s advisable not to search for a very long paragraph, rather limit it to two or three lines maximum.
If there’s any matching content available on the internet, Google will return the results with web pages where it’s published.
However, the limitation with this method is that you have to do it manually for every content piece you may want to check by taking multiple random samples. So it’s suitable only for small sites with limited content.
If you want to check for multiple pages of bigger sites, then you’d want to use advanced tools.
Use External Tools
There are plenty of free and premium tools that can help you find duplicate content issues within your site and across the domains.
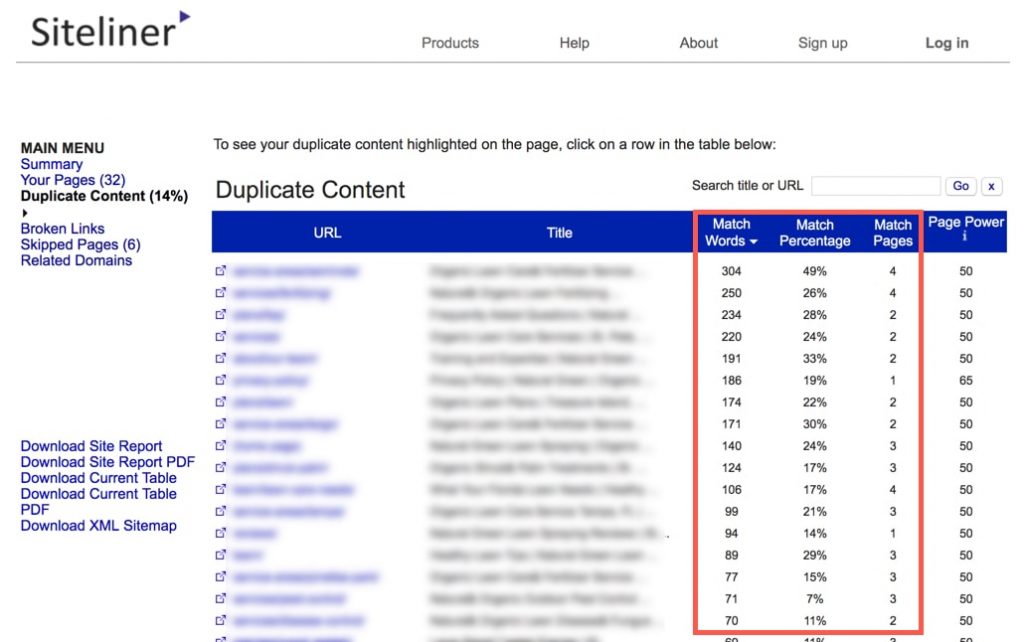
For instance, you can simply enter your website URL in the Siteliner tool and it’ll analyse your site for internal duplicate content.
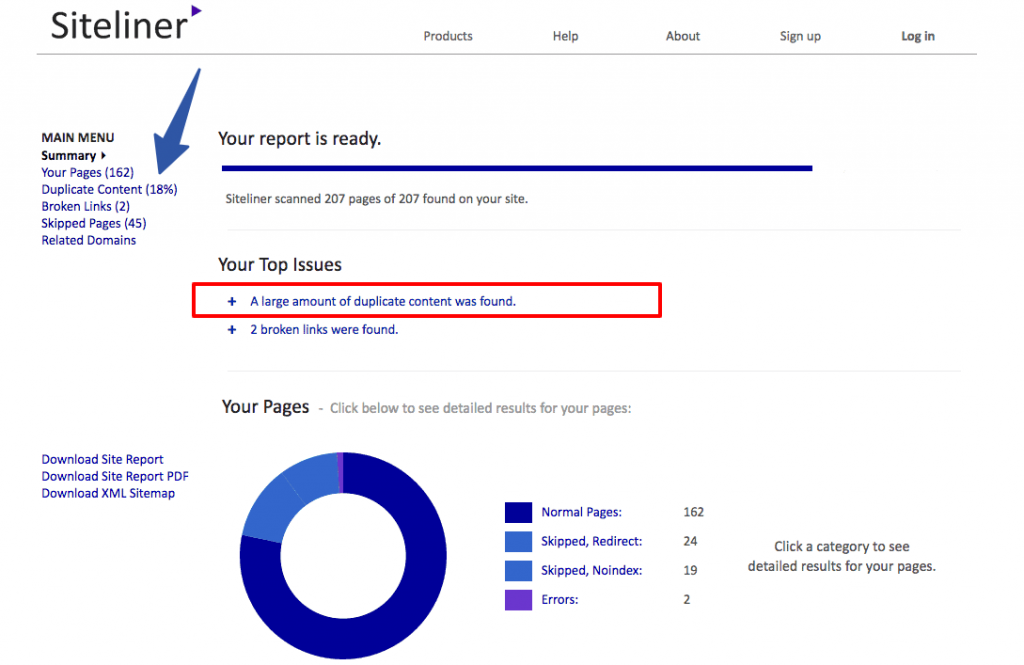
You can also view a detailed report on the duplicate content on your site.
Similarly, you can detect cross-domain duplication with Copyscape. If you suspect that your popular content is being copied, just enter the URL in the tool and it’ll show you the pages that match your content.
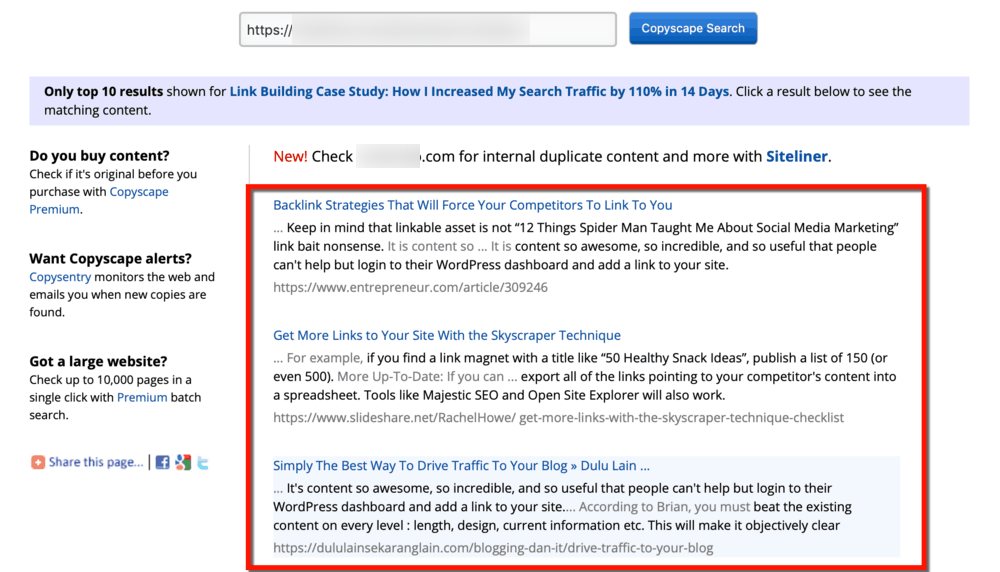
Thus, you can use the above tools to identify duplicate content issues within your website and also on other sites.
Google Search
Here’s another simple way to detect content duplication in your site.
Try searching for a keyword that your site ranks for in Google. Then observe the search results.
If you see any unfamiliar or non-user-friendly URL of your content, it means that your site has generated internal duplicate content.
Pro Tip: Use “ “ with blocks of text from your content. E.g. < ”your content” > and search in Google to see if someone has published the exact same content.
Ways to Get Rid of Duplicate Content
Now that you know how to find out the duplicate content issues within the site and across the domains, let’s understand how to deal with both.
First, we’ll talk about dealing with issues where content is stolen from your site and it’s published on other platforms.
Since you can’t remove the copied or scraped content from other sites, you can consider:
- Reaching out to the site owners and requesting them to remove the content
- Asking them to add a canonical tag linking to your original content
- Reporting it to Google and seek their help in removing such content
That said, here are the tips to help you prevent content duplication within your site.
1. Use Canonical Tags
If you’re running an eCommerce site or you syndicate content frequently, you stand a higher chance of having multiple URLs leading to the same content on your site.
So you need to help search engines find the original content by using the rel=canonical tag on the duplicate page. It’s a way to inform Google that it’s a copy.
To do it right, ensure you add the rel=canonical attribute with the URL of the original page to the HTML head of each of the duplicate pages.
For example:
<link rel=”canonical” href=”<URL of the original page>”
So if the original URL is https://www.domain.com, then the canonical tag should look something like this:
<link rel=”canonical” href=”<https://www.domain.com>”
Although it’s a simple process, it can hurt your search performance if you don’t get it right. Hence, make sure the URL in the canonical attribute exactly matches the URL of the original page.
2. 301 Redirects for Duplicate Content
The rel=canonical tags still keep the duplicate pages accessible through the search results. So if there are automatically generated duplicate pages that are not required to be seen by the users, you can use 301 redirects to send them to your preferred web page.
This will signal Googlebot to rank the original page in the search results instead of showing multiple pages with the same content.
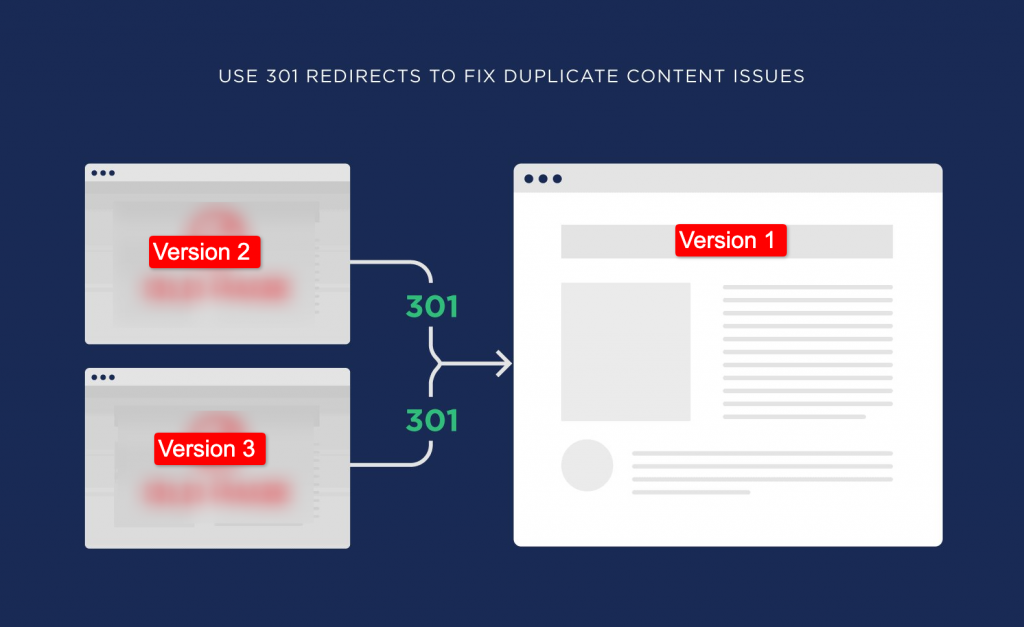
Thus, stronger relevancy and authority is passed to your preferred page and it enhances its ranking potential.
You can also use 301 redirects for multiple URLs that lead to your homepage.
Again, the word of caution is that 301 is a permanent redirect. So be careful while choosing the preferred pages you want your users to see.
You may also want to consider hiring external consultants or professional SEO services if you’re not sure how to go about 301 redirects.
3. Internal Linking Consistency
Ensure that you have consistency in your internal linking practice.
Let’s say, https://www.domain.com is the canonical version of the page. Now when you want to internally link the page, make sure you mention the exact URL instead of linking with different URLs like www.domain.com or http://domain.com, etc.
This will help you distribute the authority to the right pages on your site and help search engines identify the original page.
4. Hreflang Tags
Search engines consider the content translated in local languages as unique pages. However, it’s more of a challenge when you’re targeting the audience in the countries that have a common language.
For example, the US, UK, and Australia. In this case, your content will be quite identical on all three sites as they all use the same language.
Hence, when you’re targeting different geographies with same language and content, use the hreflang tags like this:
- <link rel=”alternate” hreflang=”en-us” href=”<https://www.domain.com>”>
- <link rel=”alternate” hreflang=”en-gb” href=”[https://www.domain.com/uk>”>
- <link rel=”alternate” hreflang=”en-au” href=”<https://www.domain.com/au>”>

This would help Google to show the right page to the audience in the targeted location.
5. Content Pagination
Let’s say you have a series of content broken up into a multi-page list, you need to let the search engines know that these pages are in sequence.
Moreover, when pagination is implemented incorrectly — without proper rel=canonical tags and internal links — it creates duplicate and orphan pages.
So ensure that you disable the pagination of the blog comments section in your CMS so that it doesn’t create different URLs of the same content with each new comment.
6. Meta Robots Tag
Another way to deal with internal duplicate content is by using the meta robots tag with noindex attribute.
You can do this by adding the code — <meta name=”robots” content=”noindex”> — to the duplicate pages.
This code indicates the search engines to exclude the page from being indexed when crawlers scan your site.
Although you don’t want Google to index these pages, you need to allow them to be crawled as Google cautions against restricting the crawl access on duplicate pages on your site.
Pro Tip: Adding noindex tag would only stop Google from indexing the pages. But it’ll continue crawling them. Thus, your crawl budget would still get wasted.
7. Set URL Parameters
You can set the preferred domain for your site in your Google Search Console.
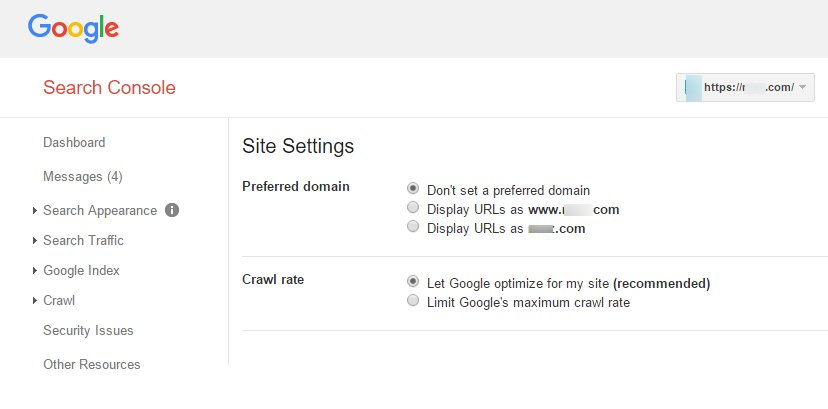
Moreover, you can also set if you want the Googlebot to crawl your site URLs differently or block the crawling of the URLs with specific parameters.
However, this process needs to be done only if needed. Get this step wrong and you might end up signalling Google to ignore the important pages of your site. So it should be performed by a technical SEO expert.
Alternatively, you can engage an SEO agency if you don’t have an in-house technical SEO specialist.
Final Thoughts
You don’t have to worry too much about duplicate content across different domains. It’s because the sites that copy or scrape the content are usually low-quality and low-authority sites.
So Google wouldn’t usually rank such sites. Thus, your ranking and traffic wouldn’t get affected as long as you’re following the right content creation and SEO practises.
However, you must keep a tab on the multiple duplicate pages being generated within your site. This affects your SEO negatively by wasting your crawl budget and diluting the link equity of your pages.
So follow the above tips and avoid internal content duplication as much as possible.

-
Bishal Shrestha
Bishal Shrestha is the Head of SEO at Supple Digital, where he leverages over 9 years of expertise to drive exceptional organic growth and digital transformation for businesses across Australia and beyond. Combining his software engineering background with cutting-edge digital marketing acumen, Bishal leads strategic SEO initiatives that consistently deliver measurable results through innovative campaigns, meticulous technical optimisation, and data-driven insights. A certified Google AdWords and Google Analytics professional, he specialises in technical SEO, content strategy, and advanced analytics, utilising industry-leading tools to craft bespoke solutions that elevate brands in competitive digital landscapes. His holistic approach and proven track record make him a trusted partner for businesses seeking sustainable online growth and market leadership.



DIGITAL MARKETING FOR ALL OF AUSTRALIA

- SEO AgencyMelbourne
- SEO AgencySydney
- SEO AgencyBrisbane
- SEO AgencyAdelaide
- SEO AgencyPerth
- SEO AgencyCanberra
- SEO AgencyHobart
- SEO AgencyDarwin
- SEO AgencyGold Coast

- We work with all businesses across Australia
