What is Index Bloat and How to Manage it?

What if we told you that deindexing or deleting some of your webpages can improve your site’s SEO performance?
Sounds uncanny? Hear us out!
While achieving 100% indexing of the important pages boosts your SEO, excessive indexing — index bloat — harms your SEO to the same degree.
Index bloat is one of the most pressing SEO issues for large websites. And sometimes you might be dealing with this challenge without even knowing that your site has one.
In this guide, you’ll learn:
- What index bloat is
- How index bloat affects your SEO
- Why index bloat happens
- How to identify index bloat
- How to fix index bloat issues
Let’s dive in.
What is Index Bloat?
When search engines index multiple low-quality pages from a website that have no search value, it’s known as index bloat. In other words, index bloat happens when Google indexes the pages from your site that shouldn’t have been indexed.
Index bloat is one of the most common SEO challenges that large websites — eCommerce, job portals, travel booking, etc. — face.
For instance, let’s assume you’re running an eCommerce website. Google visited your XML sitemap and found 40,000 pages.
However, while crawling your site it finds many more pages. These pages might have been created due to search filters in product and category pages producing numerous facet combinations. So Google ended up indexing 400,000 pages from your site.
Now all of these pages wouldn’t offer unique value to users because most of them would be internal duplicate pages. That’s index bloat, precisely.
How Does Index Bloat Affect SEO?
Index bloat might be hurting your SEO efforts beyond your awareness. Besides slowing down your website, index bloat can cause multiple serious SEO issues for your site.
Here they are.
Wastes Crawl Budget
Search engines crawl sites to find and add new pages to their database. Thus, when a searcher enters a query in Google, it serves the most relevant results for their query.
However, Google won’t crawl all the pages on a site. It assigns a crawl budget for every site. In other words, it would set a limit on the number of pages it’ll crawl from each site.

Let’s say your site has index bloat issues. Now, when Googlebot crawls your site, it would get confused on seeing thousands of low-quality pages. So it may end up wasting your crawl budget on these pages and your important pages might stay unindexed.
Creates Orphan Pages
Search filters or faceted navigation can automatically create multiple variations of URLs on large sites. So it’s obvious that you wouldn’t even know that they exist on your site.
Consequently, you wouldn’t bother adding these pages to your sitemaps and internal linking structure. Thus, these pages wouldn’t have any internal links. In the context of SEO, they are called orphan pages.

Also, Google assumes that since these pages are not linked within the site, they’re not important. Thus, having thousands of unimportant pages on your site would decrease your domain’s quality standards from an SEO perspective.
Impacts Ranking Negatively
As discussed, index bloat can result in a situation where your site’s important and relevant content may stay unindexed and duplicate pages are indexed.
Now, these low-quality or duplicate pages are unlikely to rank for users’ search queries. It’s because Google focuses on delivering the most relevant and reliable information in search results. So Google may prefer serving relevant content from other sites.
Thus, it could lead to dropped rankings for your website. And before you realise it, this can spiral into reduced traffic and conversions eventually.
So if you think that your website ranking and traffic are affected for reasons unknown to you, consider consulting an SEO agency for a site audit.
Why Does Index Bloat Happen?
Now, let’s discuss the factors that cause index bloat on your website.
Faceted Search
Faceted search or faceted navigation allows users to filter the search results within a website. It’s typically used by large websites.
Most eCommerce sites use faceted navigation to help their shoppers narrow down choices from thousands of product options.
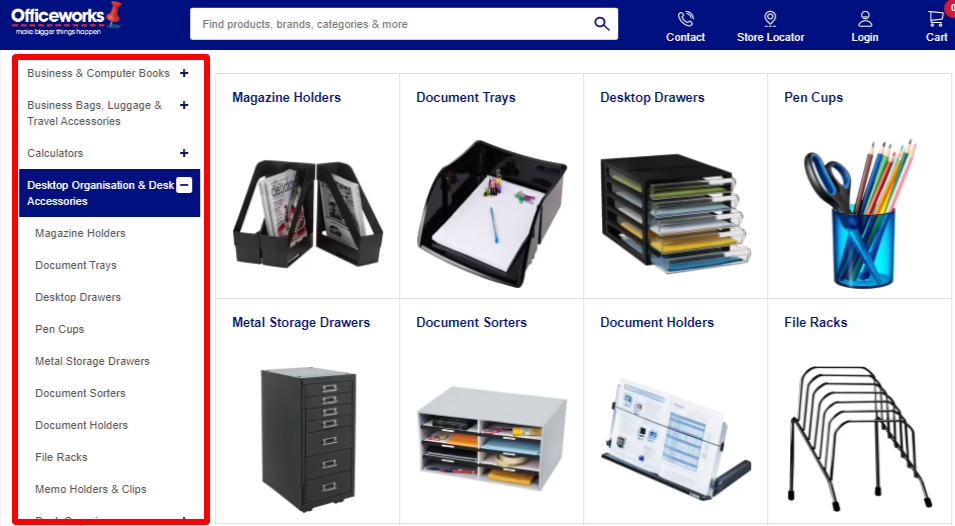
If not dealt with correctly, this very feature that adds to the user experience (UX), is capable enough to create millions of duplicate pages within your site.
Duplicate Content
Apparently, faceted navigation is also one of the key reasons for internal content duplication on large websites.
Nonetheless smaller sites can also have duplicate content issues due to reasons such as:
- URL variations: Multiple URLs leading to the same page. E.g. https://www.domain.com, https://domain.com, http://www.domain.com.
- Domain localisation: For instance, having a .com.au or .au domain version for Australia and .de for Germany if you’re operating in multiple countries.
So when Google indexes all these duplicate pages as unique URLs, it would lead to index bloat.
Pagination
Pagination is dividing content into a series of pages to make it more organised and accessible to users.
For instance, here’s how Ahrefs manages its SEO blog archive — 10 posts per page and then the next 10 on the second page and so on.
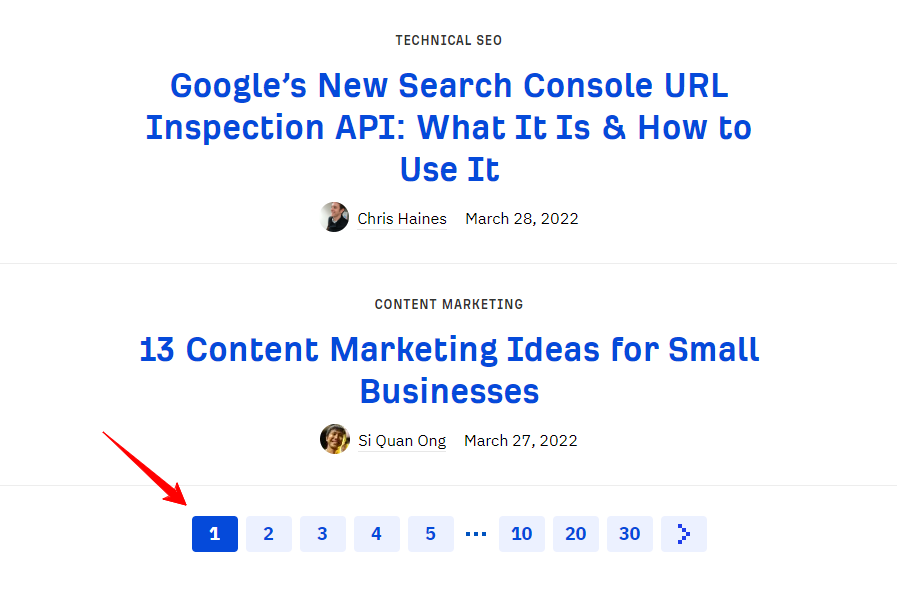
Similarly, websites like eCommerce, news and media, etc. manage their pages like this. So it creates URLs like:
- https://www.domain.com/blog/
- https://www.domain.com/blog/page/2/
- https://www.domain.com/blog/page/3/
Google may index all these URLs as unique pages. At the same time their page title, meta description, etc. will remain the same and body content would be very similar. So if it’s not handled correctly, it can cause duplicate content issues.
Furthermore, when you create campaign-specific landing pages and don’t de-index once your marketing campaigns are over, they’ll get indexed too. Whereas you don’t want such dead pages from your site in Google’s database.
Identifying Index Bloat
Now that we know what index bloat, why you don’t want it, and its causes, let’s learn how to detect whether your site has this issue.
Google Search Operators
Although not 100% indicative and the only method you should rely on, searching with Google Search Operators can give you some quick initial hints of index bloat.
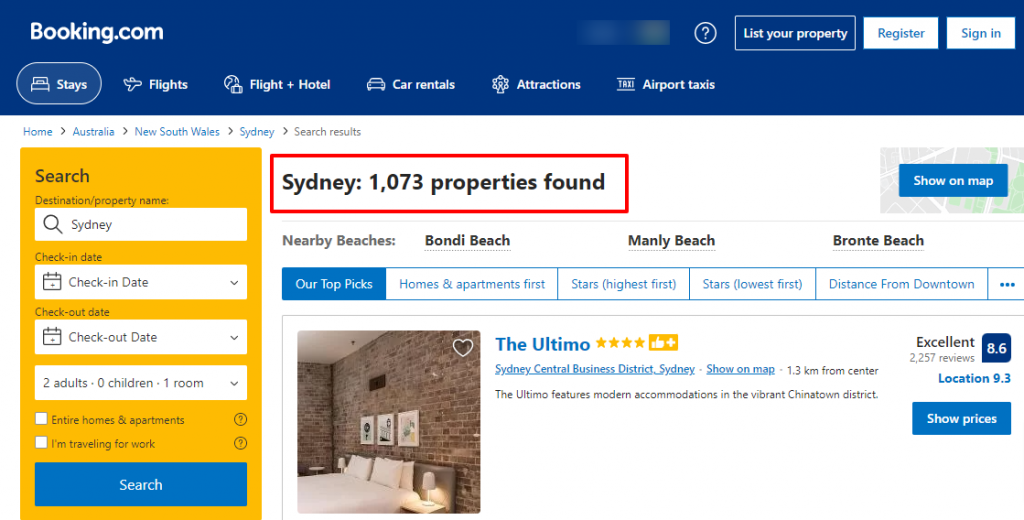
For example, on Booking.com they’ve listed 1073 properties to stay in Sydney.
Now, let’s do a quick site: search on Google for:
site:https://www.booking.com/ “hotels in sydney”.
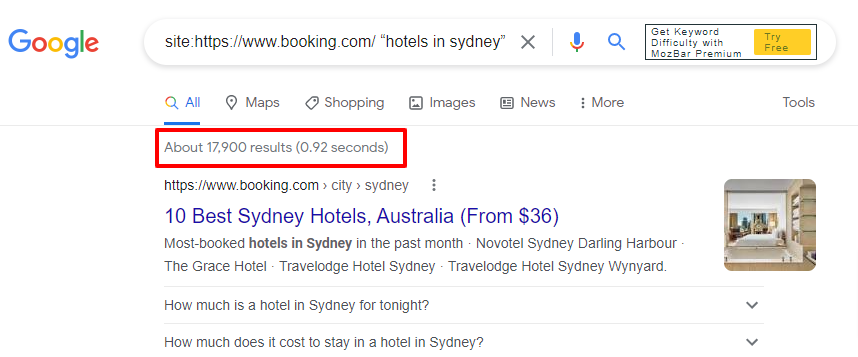
Note: We’ve shown this example for illustrative purposes. It doesn’t confirm that the website used as an example has index bloat issues. Moreover, there could also be general Sydney pages in the results.
As you can see, Google has indexed 17,900 pages from Booking.com’s site for the search term “hotels in sydney”.
That’s almost 18 times indexation. And this is just for one city. Now imagine the number for the entire site considering that Booking.com operates globally in more than 200+ countries.
Google Search Console
Another way to know the number of indexed pages from your site is by logging into your Google Search Console (GSC) account. And click Google Index > Index Status.
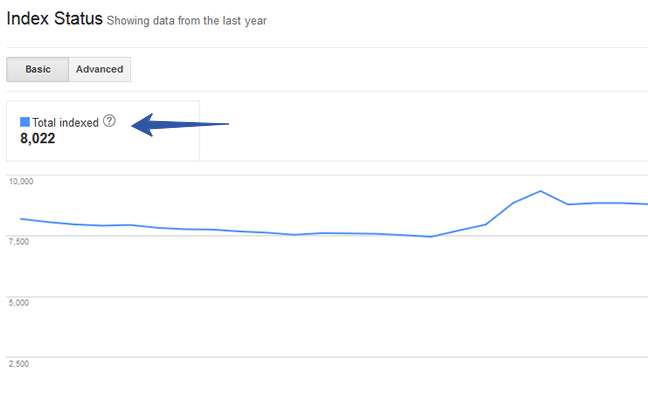
Now as a website owner or SEO specialist, you’d know the approx number of pages that should get indexed from your site.
So if the number that GSC shows is exceedingly larger than what you expected, it’s a sign of potential index bloat.
You need to dig deep into advanced reports to find the issues. If you’re not sure how to go about it, you can hire external SEO services to get accurate consultation and resolution.
Crawling Tools
Alternatively, you can use crawling tools like Screaming Frog or Sitebulb. These tools crawl your sites as search engines do and give you a detailed report on your site’s indexation.
Moreover, they can precisely provide you with the pages that are causing duplicate content and index bloat.
Once you have the culprit pages identified, you can deal with them. That’s what we’re going to discuss next.
How to Fix Index Bloat Issues
Once you figure out how to detect index bloat and the pages that cause them, all that’s left is fixing these issues.
Here are some potential solutions.
Using Meta Robot Tags
One of the effective ways to solve index bloat is using meta robot tags. They inform Google not to index the pages where you’ve applied these tags.
So once you have your list of such pages ready, you need to add the meta robot tags in their header using this code:
<META NAME=”ROBOTS” CONTENT=”NOINDEX, FOLLOW”>
Since you’ve specified here “NOINDEX, FOLLOW”, it’s a message to search engines that they shouldn’t index them, but they can follow the links on these pages. This will ensure that Google can access the other pages through these links without indexing the page.
Canonicalisation
The most preferred method to stop indexing the multiple versions of the same page is by adding canonical tags to these pages. It’s also an ideal way to deal with duplicate content issues.
When you add the canonical tags on duplicate pages, it guides Googlebot to the original page when it crawls them.
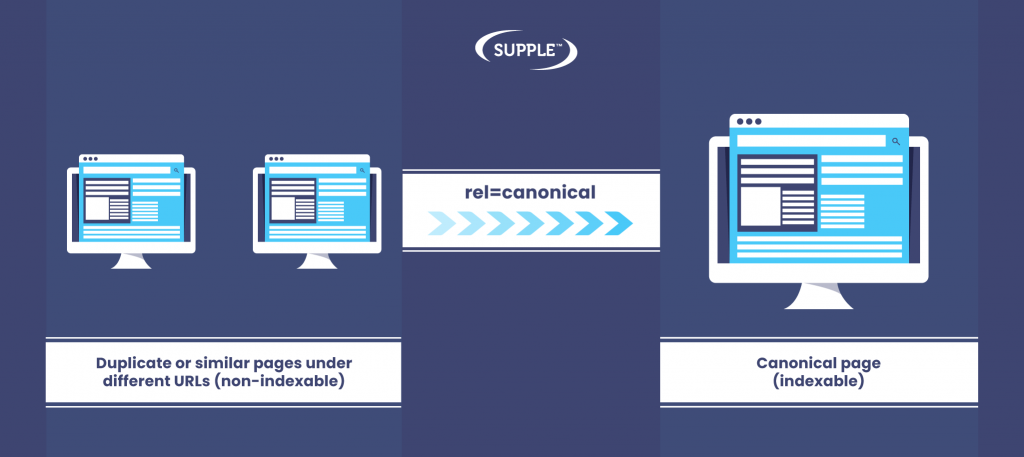
To apply the rel=canonical attribute, you need to go to the header section of the duplicate pages and add this code:
<link rel=”canonical” href=”<URL of the original page>”
Thus, when Googlebot visits the pages with a canonical tag, it would understand that they’re not the original (or canonical) version of the page. So it’ll avoid indexing them.
Besides preventing indexation of duplicate pages, canonical tags also consolidate the link equity from these pages and pass it to the main page.
301 Redirects
At times some of the old pages that no longer exist on your site may still be there in Google’s database. This can also cause index bloat if the number of such pages is in high volume.
Although Google would eventually de-index them, there’s no defined timeline for it. So to speed up the process, you can 301 redirect these URLs to relevant pages.
This prompts Google to remove the dead pages from its index list.
Use Robot.txt File
The challenge with all the above methods — meta robot tags, canonicalisation, and 301 redirects — is that you have to do it for each URL variation or duplicate page manually.
Hence, they’re feasible for smaller websites. However, if you’re operating a large website with hundreds of thousands of pages, these solutions can take up a lot of time.
In such cases, you can create a robot.txt file and disallow the crawling of specific pages or parameters. It’ll look something like this.
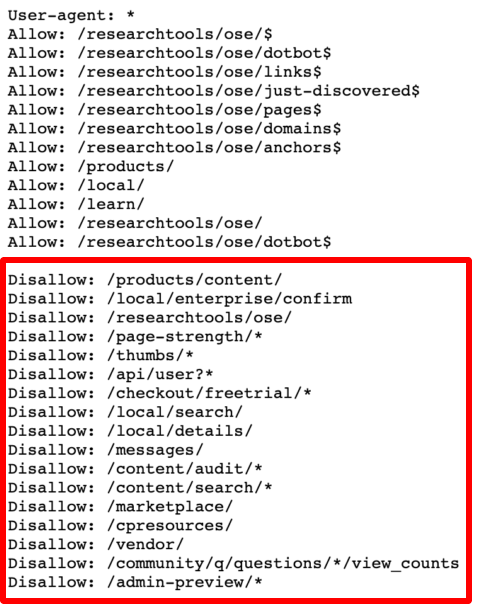
However, if there are internal links pointing toward these pages then they’ll get indexed even if you’ve blocked them from getting crawled. So you’d need to either add the nofollow tags or remove the internal links from these pages.
URL Parameter Tool
If none of the above methods works, you can consider setting the URL parameters in GSC.
This allows you to tell Google how to handle URL parameters on your site.
To set the URL parameters, go to the URL parameters tool in GSC and click add the parameter.
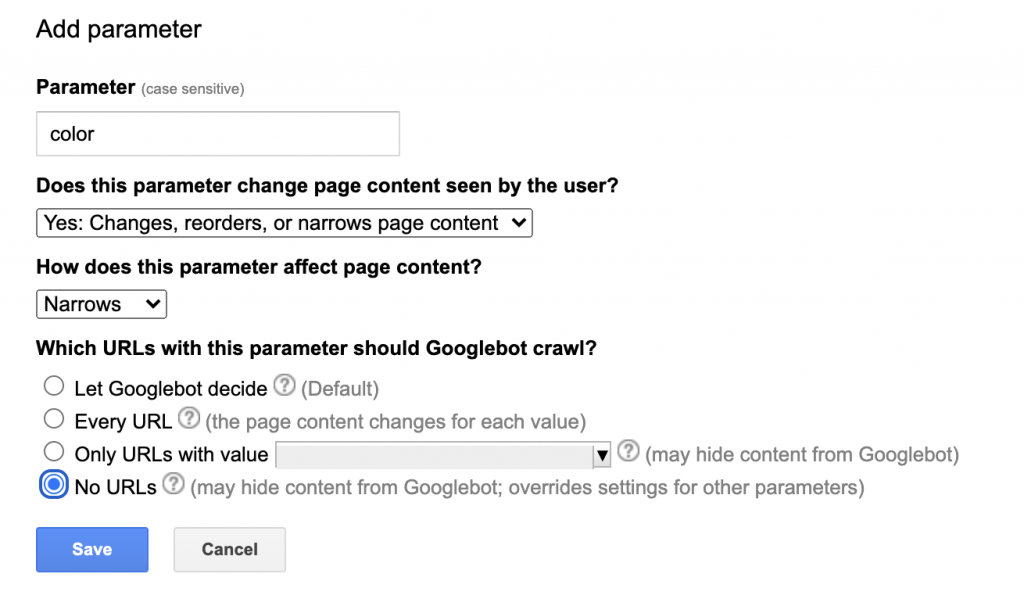
Thus, here you can set your preferences as to how Googlebot should crawl URLs with specific parameters. Also, whether it should crawl them or not.
Note: URL Parameter Tool is going to be removed from GSC soon. So while we have mentioned it here as a reference, don’t rely on it as a long-term solution.
Delete Pages
Even after using the URL parameters tool, if some unwanted pages remain indexed, then you need to delete these pages from the Google index.
You can do this by using the URL removal tool in GSC. Add the list of URLs that you want to be removed from the index and submit it in GSC. Google usually processes this request within a day or same-day sometimes.
While this is a quick way to get rid of the unwanted URLs from the index, it’s also a temporary fix. So ensure that you’re taking the right measures discussed above to prevent their reindexing in future.
Final Thoughts
So now that you know how to detect and fix the index bloat issues on your website, it’s time to get rid of them.
At the same time, it’s recommended that you let your technical SEO expert apply the above solutions. If you get it wrong, it may also affect the indexing of your important pages.
Furthermore, you can consult our expert SEOs if you find it challenging to resolve index bloat issues in-house.

-
Bishal Shrestha
Bishal Shrestha is the Head of SEO at Supple Digital, where he leverages over 9 years of expertise to drive exceptional organic growth and digital transformation for businesses across Australia and beyond. Combining his software engineering background with cutting-edge digital marketing acumen, Bishal leads strategic SEO initiatives that consistently deliver measurable results through innovative campaigns, meticulous technical optimisation, and data-driven insights. A certified Google AdWords and Google Analytics professional, he specialises in technical SEO, content strategy, and advanced analytics, utilising industry-leading tools to craft bespoke solutions that elevate brands in competitive digital landscapes. His holistic approach and proven track record make him a trusted partner for businesses seeking sustainable online growth and market leadership.



DIGITAL MARKETING FOR ALL OF AUSTRALIA

- SEO AgencyMelbourne
- SEO AgencySydney
- SEO AgencyBrisbane
- SEO AgencyAdelaide
- SEO AgencyPerth
- SEO AgencyCanberra
- SEO AgencyHobart
- SEO AgencyDarwin
- SEO AgencyGold Coast

- We work with all businesses across Australia
